Core Technical Advantages
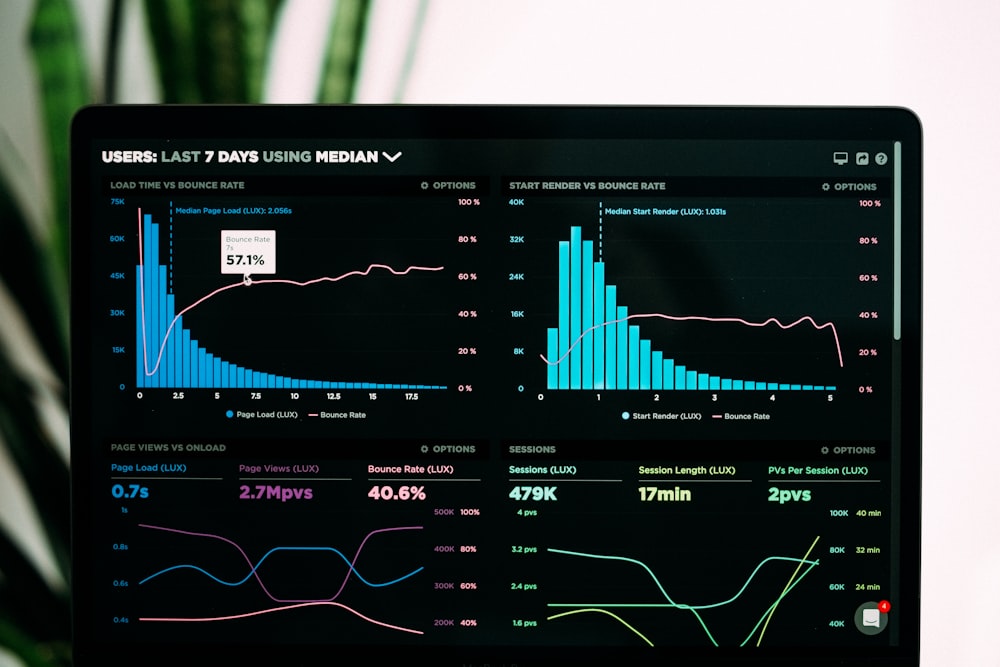
Syna possesses a top-tier algorithm team deeply rooted in the audio/video field. We are dedicated to solving speech interaction challenges in complex acoustic environments by combining deep learning with traditional signal processing.
Our algorithm solutions feature low power consumption, low latency, and high robustness. They are widely adapted to various embedded chip platforms, providing customers with full-stack solutions from algorithm licensing to software-hardware integration.